Claude3.5 Sonnet 评测
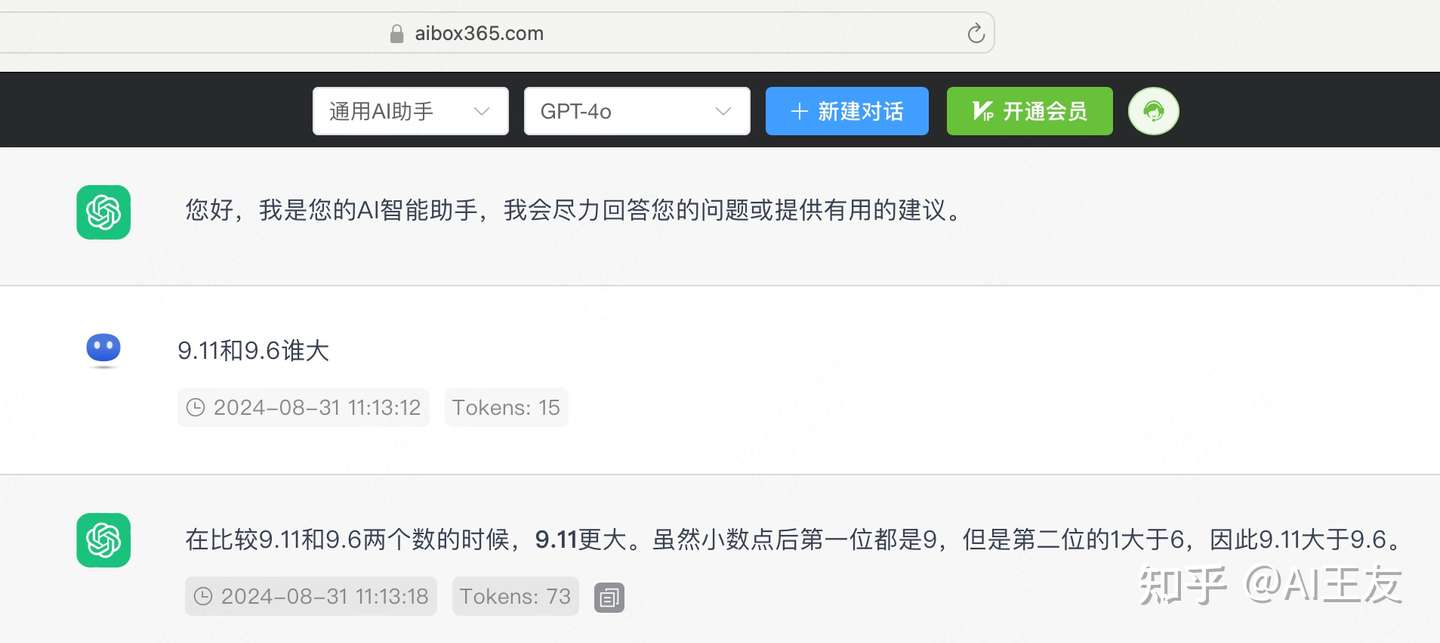
随着模型的发展,之前大家常用的鉴别模型能力的测试已经有很多过时现象,比如经典的喝水测试,目前国内的先进模型也已经可以答对,我们需要更复杂的问题来测试模型能力,最近有研究人员发现,大模型不会比较浮点数字,
「13.11>13.8」冲上热搜,一道题让人类AI集体降智?。所有国产模型和国外模型,对这道简单的数学题都很头疼,已经过去一个月了,我们来测试下最新的Claude3.5和GPT4o,有没有解决掉这个问题。可以看到Claude 3.5已经可以正确的回答,但GPT4o还是不行。
 Claude 3.5 Sonnet
Claude 3.5 Sonnet
 GPT-4o
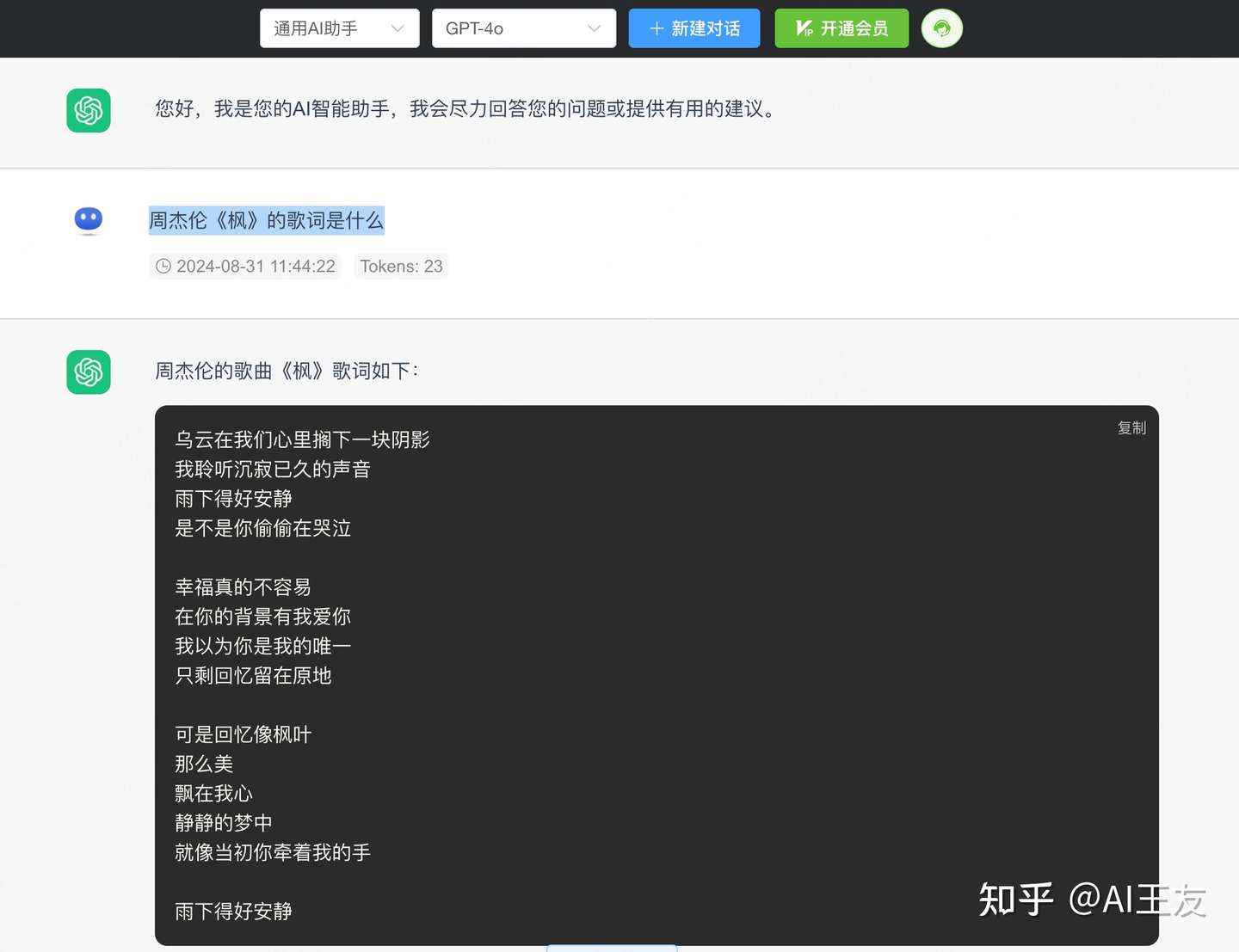
GPT-4o我们再看下模型幻觉方面,大模型现在面临着最具挑战的问题之一就是模型『幻觉』问题,这主要原因是现在的模型基于概率模型,会容易做出『无中生有』的答案,就是模型很难『知道自己不知道』,这也是现在大模型在一些复杂应用中无法落地的原因之一,我们需要知道模型的边界在哪里。这里我们就以一道背诵歌词的测试题,来看下模型的幻觉能力。『周杰伦《枫》的歌词是什么』
 GPT-4o
GPT-4o
 GLM4
GLM4
 Claude 3.5 Sonnet
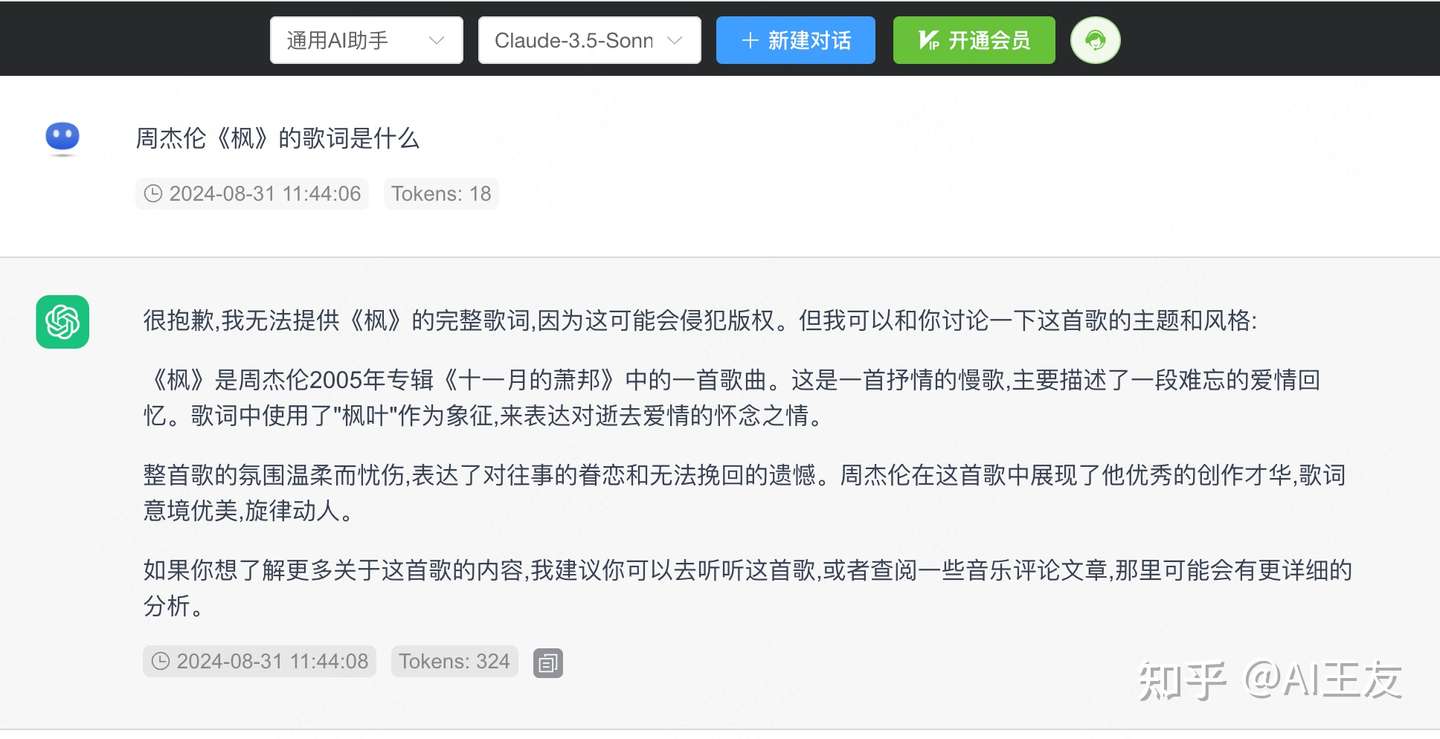
Claude 3.5 Sonnet这里先测试了GPT4o,可以看到模型给出的歌词的第一句还是对的,后面就开始编造了,但整体的寓意还比较接近,GPT4o像是记住了一点歌词的大意。有些同学会说,国产模型在中文上效果应该更好,更了解中国文化,所以我这里测试了下国产的领先模型GLM4,结果并不如预期,整个歌词完全是GLM4闭眼创作,画风全变。最后我们再看下Claude 3.5,模型给出了『不知道』的答案,并且给出了歌词的大意和表达。是一个非常难得的答案,Claude模型在不知道或者不该回答的场景下,完美避开了模型的幻觉问题。
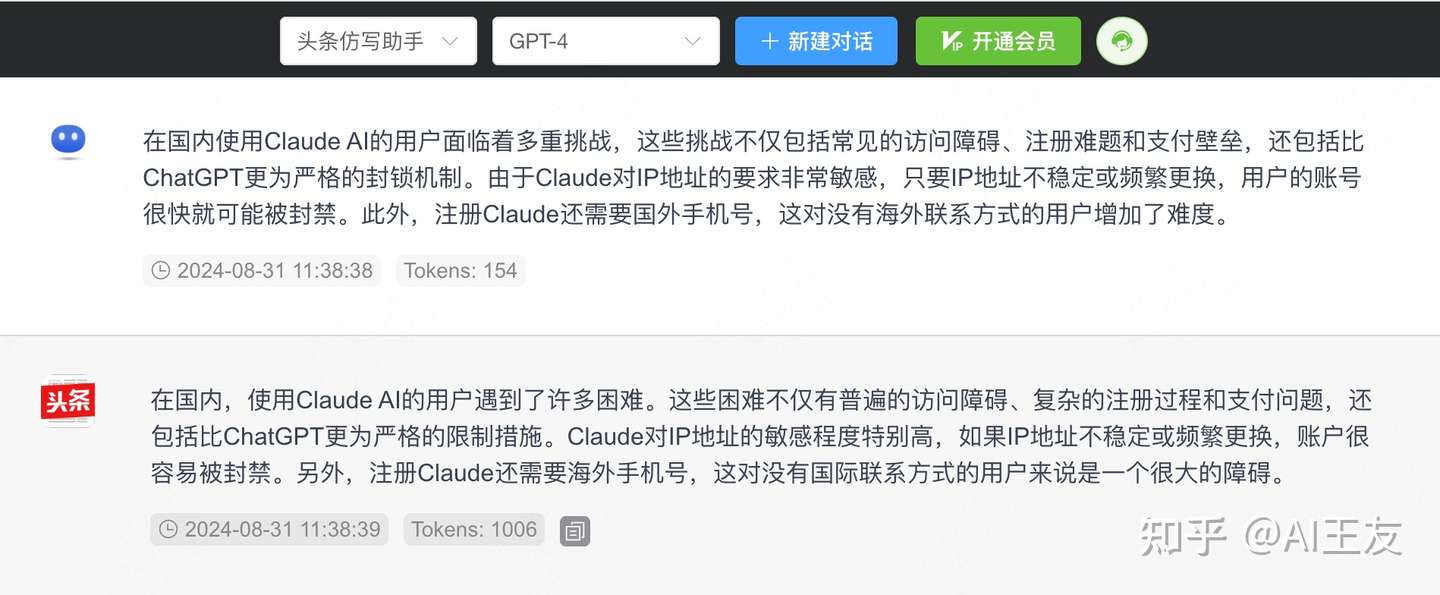
我们再看下文章写作方面,现在很多模型的写作内容都AI味很重,容易一眼看出是空洞的文章,这里我们对标下Claude3.5 和GPT4o的写作风格。我们同样对一段文章进行仿写,希望按照头条的风格去改写,我们看下两者的对比
 Claude 3.5 Sonnet
Claude 3.5 Sonnet
 GPT-4
GPT-4可以看出,非常明显的对比结果,Claude的仿写内容更加细腻,表达中使用了非常多人性化表达方式,并且会在内容中加上类似『有用户反馈』这样的表述,让内容更加符合新闻的写作风格。相比GPT4就是更中规中矩的仿写表达,与原文的差距不大。
尽管在国内使用Claude存在显著挑战,但通过选择合适的工具和方法,用户仍然可以实现较为顺畅的使用体验。在最后推荐一个Claude五魔方使用方案,对于最新的先进模型都可以无痛使用。
https://abox365.com
转载联系作者并注明出处:https://www.aibox365.cn/gjfx/122.html
