AI语言模型逐渐成为人们日常工作和生活中的得力助手。OpenAI的ChatGPT和Anthropic的Claude无疑是其中的佼佼者。自ChatGPT在2022年发布以来,它迅速吸引了大量用户。而Claude作为其主要竞争对手,也在2023年推出,凭借其独特的功能和优势赢得了一席之地。
本文将从多个角度对比ChatGPT和Claude 3.5,让你能够更好地选择适合自己的AI助手。
一、性能与功能对比
Claude 3.5的优势: Claude的最大亮点之一是其更大的上下文窗口,能够处理高达200,000个token的数据量,而对于特定场景,还可以扩展至1,000,000个token。相比之下,ChatGPT-4o的上下文窗口为128,000个token。
ChatGPT的优势: ChatGPT在功能上更加全面,尤其是其多模态AI模型GPT-4o,可以处理图像生成并具备互联网访问能力,而Claude在这些方面略显不足。ChatGPT支持的语言种类超过95种,覆盖面更广,能够满足多语言环境下的使用需求。
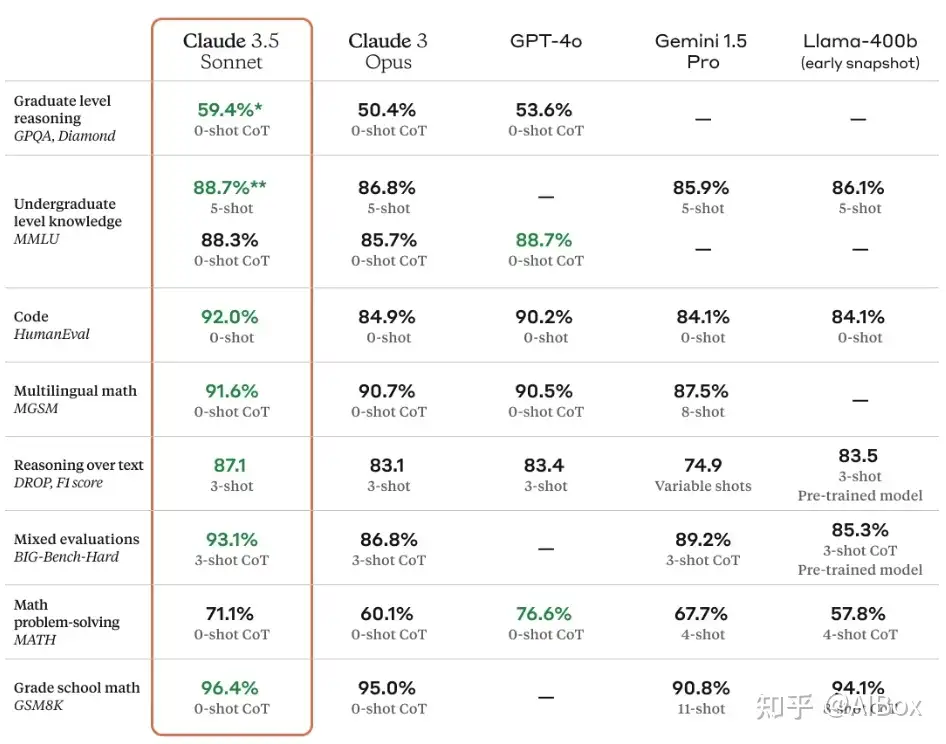
从公开的学术评测角度看:Claude3.5 在学术榜单上具有一定优势,当然GPT4o 8月份已经发布了新的版本,在榜单上的胜负可能会有动态变化。
二、实际应用场景对比
1. 创意性任务:Claude 更加擅长
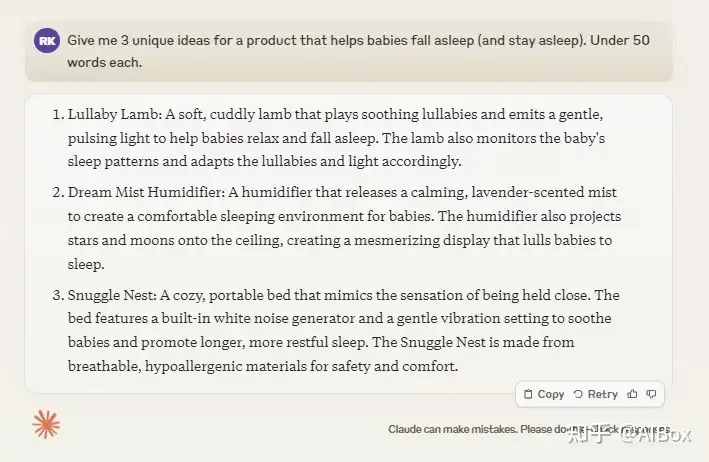
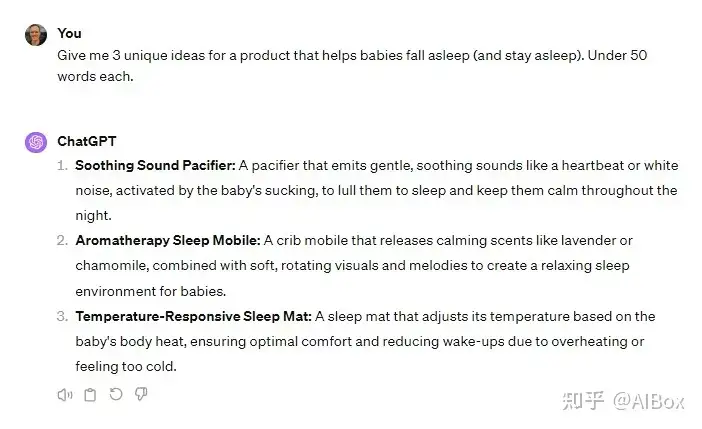
Claude 的默认写作风格相比 ChatGPT 更接近人类语言,输出显得不那么公式化。例如,在一次头脑风暴中,我要求两个模型为婴儿睡眠产品提出创意。Claude 提出了一个名为“摇篮小羊”的想法,它带有轻柔脉动的灯光,有助于哄宝宝入睡。而 ChatGPT 则提议了一个“温度响应睡垫”,虽然也是独特的想法,但听起来更像是潜在的安全隐患。最终,Claude 的创意显得更贴近实际需求。
在另一项创造性写作测试中,我要求模型编写一个带有戏剧性反转的短篇故事。Claude 的故事结尾更具戏剧性和冲击力,而 ChatGPT 的故事转折则显得相对平淡。虽然两个模型的写作质量相近,但 Claude 的故事情节设计显得更为出色。


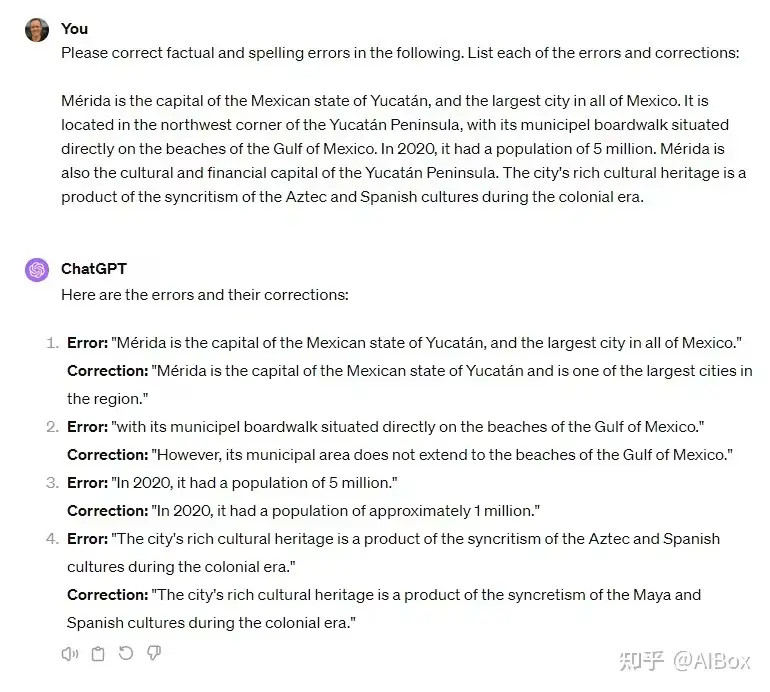
2. 校对和事实核查:Claude 更加可靠
在校对测试中,我给两个模型提供了一段包含拼写错误和事实错误的文字。Claude 能够准确识别出所有错误,并逐条列出,清晰易懂。而 ChatGPT 虽然也识别出了错误,但它直接重写了整个段落,而不是一一指出具体的错误位置,这使得理解问题所在变得更加困难。

在事实核查方面,Claude 和 ChatGPT 在回答“解释给5岁小朋友”的问题时表现都很好。但在处理复杂事实时,Claude 的输出更清晰、更直观。两个模型都可能偶尔出现“幻觉”现象,但 Claude 在编辑和校对时表现得更加稳健。
3. 图片处理:两者在场景理解上表现类似,但 Claude 更加灵活
在图片处理和理解任务上,Claude 和 ChatGPT 都展现了相对不错的能力,但在处理细节和复杂视觉信息时,仍然存在一定局限。
首先,我让两个模型对一张室内设计图提出改进建议,图片中包含一个普通的客厅场景。Claude 和 ChatGPT 都能够准确识别出图片中的主要元素,如沙发、茶几、灯具等,并给出了相应的设计建议。Claude 的建议更具灵活性和创造性,比如“使用更多的自然光源来提升空间感,建议在墙上加装一面镜子以增强光线反射”,而 ChatGPT 则更多集中在常规建议上,比如“换掉棕色沙发为浅色,提升房间亮度”。
在图片中的物体计数任务上,比如让两个模型数一数一张水果盘中有多少个水果,Claude 和 ChatGPT 的表现都有待提升。Claude 尝试避免给出确切的数量,转而使用模糊的表述方式,比如“盘中有多个水果”,而 ChatGPT 则会直接尝试给出一个具体的数字,尽管不总是准确。
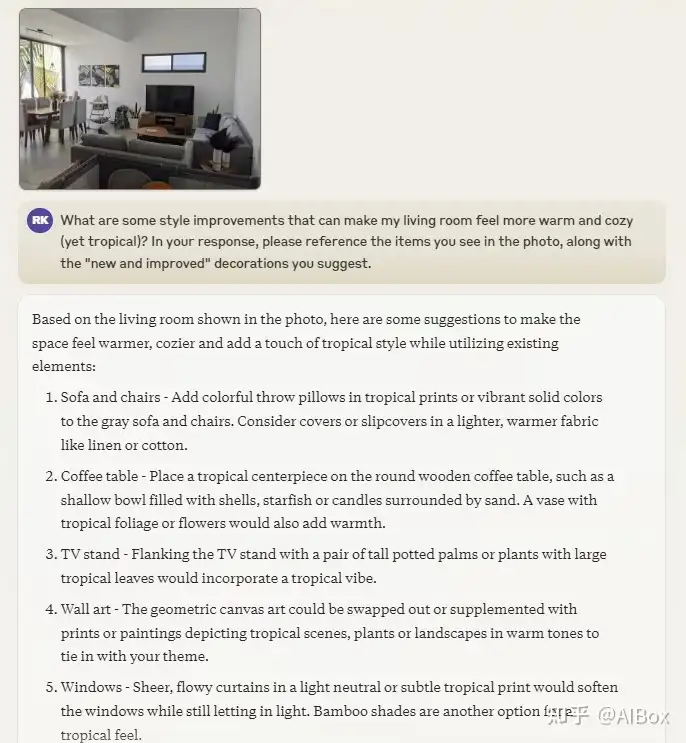
对于图片细节的处理,Claude 的优势在于其更加灵活的语言表述和对图片情景的创造性建议,而 ChatGPT 则更倾向于提供结构化和直接的反馈。例如,在要求他们对一张照片进行情感描述时,Claude 能够从场景的细节出发,提供一个更具人情味的解释,比如“这间房间营造出一种温馨的家庭氛围,似乎在呼唤着家庭成员共度美好时光”。而 ChatGPT 的描述则更偏向于中立的陈述,比如“房间的摆设很整齐,光线较好,适合家庭使用”。
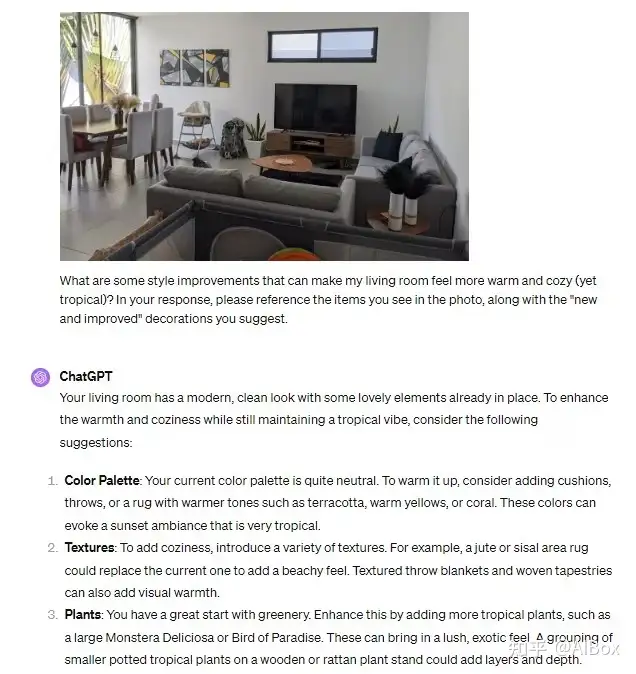
4. 逻辑和推理:ChatGPT 在复杂问题上展现了更好的组织和解释能力
在逻辑推理和复杂问题的解答任务中,ChatGPT 展现了更为系统和缜密的推理能力,尤其是在解答多步骤的问题时,它的逻辑清晰度更高。
一个经典的测试场景是要求两个模型解答一道复杂的物理学问题,题目涉及多个变量的推导。ChatGPT 在这一测试中表现出色,不仅详细说明了每个推导步骤,而且在提供解释时使用了简洁明了的数学符号,极大地提高了可读性。例如,在解答涉及牛顿力学的题目时,ChatGPT 清晰地列出了公式推导过程,并对每个物理量的意义进行了详尽解释,仿佛在跟你面对面授课一样。

相比之下,Claude 的表现稍显逊色。在解决逻辑推理问题时,Claude 的叙述方式有时显得过于冗长,虽然它最终也能得出正确答案,但在多步骤的过程中,它的推理链条不如 ChatGPT 那么紧密。有时候,Claude 会给出一些额外的背景信息,这在某些情况下有帮助,但也可能导致答题过程不够直接。例如,在解释某个物理现象时,Claude 会扩展到物理背后的哲学或历史背景,而不是立即进入问题的核心计算。

5. 数学推导:GPT4o准确率上更好些
在处理数学应用题方面,Claude 3.5 Sonnet 和 GPT-4o 相比它们的前身都展示了进步。然而,在具体表现上,ChatGPT 在这类任务上更胜一筹。
当我使用 Claude 3 Opus 进行测试时,它并未提供完整的答案,而是仅给出了一个最终方程,留给我自行解决。而 Claude 3.5 Sonnet 在解答过程中接近了正确答案,但仍然最终给出了错误的结果。例如,当被要求解决一个涉及多个步骤和变量的数学问题时,Claude 3.5 尽管展示了理解问题的逻辑能力,但在处理过程中某些细节的错误导致了错误的答案。

相比之下,GPT-4o 在数学推理上表现出色,它成功地解决了相同的问题,并且提供了正确答案。这次,ChatGPT 展示了其对于步骤推理、变量运算的精准掌握,在多步运算的数学问题中表现出更为细致的计算能力和逻辑推理能力。这一表现超越了其前身 GPT-4。

6. 代码编程:Claude 3.5 Sonnet 新功能“Artifacts”交互更有优势
在编程能力的测试中,Claude 3.5 Sonnet 和 GPT-4o 都展示了其在代码生成方面的能力。然而,由于我是一个初学者,测试过程中Claude 3.5 Sonnet 的新功能“Artifacts”引起了我的特别关注。Artifacts 允许用户实时预览代码的结果,这对于代码调试和开发尤为有用。当我尝试创建一个简单的视频游戏时,Claude 的这个功能使得实时查看和修改游戏效果变得更加直观和高效。
例如,我尝试用 Claude 创建一个类似 Frogger 的经典游戏。Claude 提供了逐步的指导,并且在游戏界面中实时显示了结果。对于我要求的修改,比如让汽车颜色更亮,并且逐渐加速增加挑战性,Claude 都能快速做出调整并展示效果。这个过程不仅让我在游戏开发中感到更加得心应手,也突显了 Claude 3.5 Sonnet 在用户交互方面的优势。

与之相比,GPT-4o 的编程能力虽然强大,但对于初学者来说则显得稍微复杂一些。虽然 GPT-4o 能够生成代码并创建类似的游戏,但没有类似于 Claude 的 Artifacts 这样的用户界面,无法在生成代码的同时进行即时预览和互动。因此,我只能依赖外部工具来运行和测试代码,这使得整个过程缺乏流畅性和直观性。
总结来看,Claude 3.5 Sonnet和GPT-4o各有所长,通过分析大家可以根据不同的任务和场景灵活选择模型。这里推荐一个一站式AI平台,可以对比Claude、GPT、Gemini等不同模型效果,无需魔法国内直达。
https://aibox365.com
转载联系作者并注明出处:https://www.aibox365.cn/gjfx/123.html
