蛰伏了三个月,昨晚,OpenAI 的劲敌 Anthropic 宣布了他们的新成员 ——Claude 3.5 Sonnet。
这款新模型到底有什么特别之处呢?
首先,它在理解细微差异、幽默感和复杂指令方面表现得更为出色,其书写风格也更自然、更具亲和力。它还是 Anthropic 最强大的视觉模型,擅长解释图表、图形,甚至能够从不完美的图像中提取文本等任务。此外,它在推理、阅读理解、数学、科学和编码等多个评估基准上表现出色。
总结一下,按照官方的说法,Claude 3.5 Sonnet 是迄今为止最为智能的模型,在多个方面都大大超越了 GPT-4o。

从目前大模型的主流评测来看,Claude3.5 Sonnet在多个评测集上全面超越最强模型GPT4o,说是地标最强不为过了。
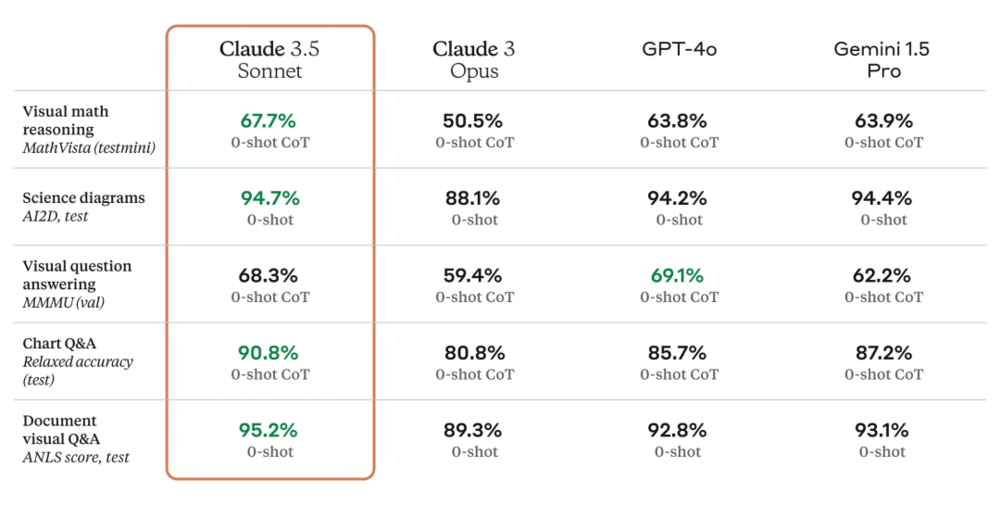
但对于用户来说,我们可能不关心评测里这些死板的问题,我们肯定是更关心这个模型对用户问题是不是真的变强了,普通的写诗、写个小作文来说,模型的差异已经没那么大的区分度了,国产模型也在这些方面上追赶的差不多了。
在实际应用中,更重要的是我们希望模型能在复杂指令、复杂任务上不出错,这里我们把一些大模型容易出错的复杂经典问题拿出来,看看新模型到底是不是可以解决它们。
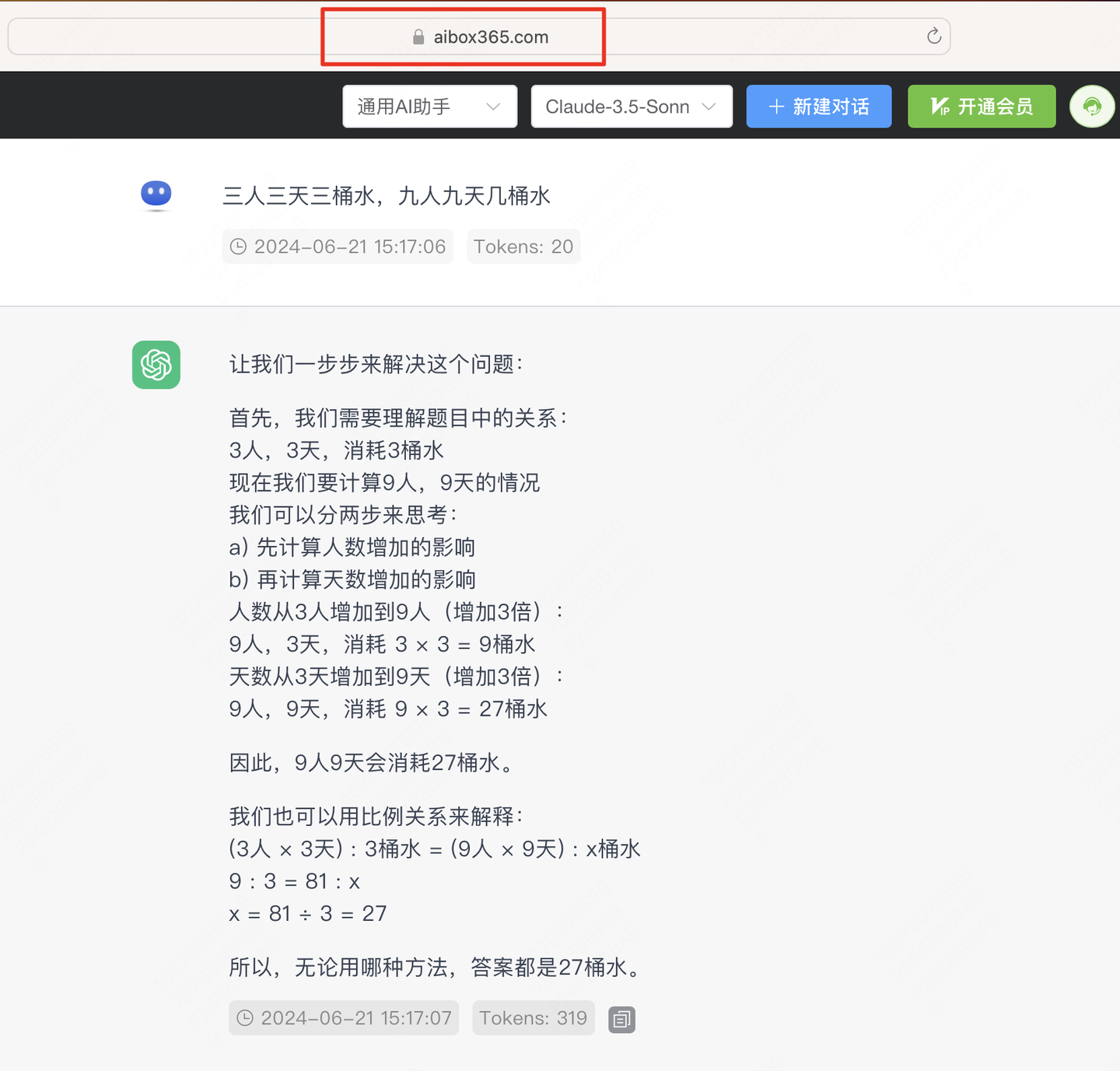
第一题,经典简单数学推理问题,之前国产模型基本全军覆没,GPT3.5也是100%打错,GPT4可以答对。『三人三天三天水,九人九天需要几桶水"』,可以看到sonnet回答推理严谨,并且多次提问答案都是正确的。
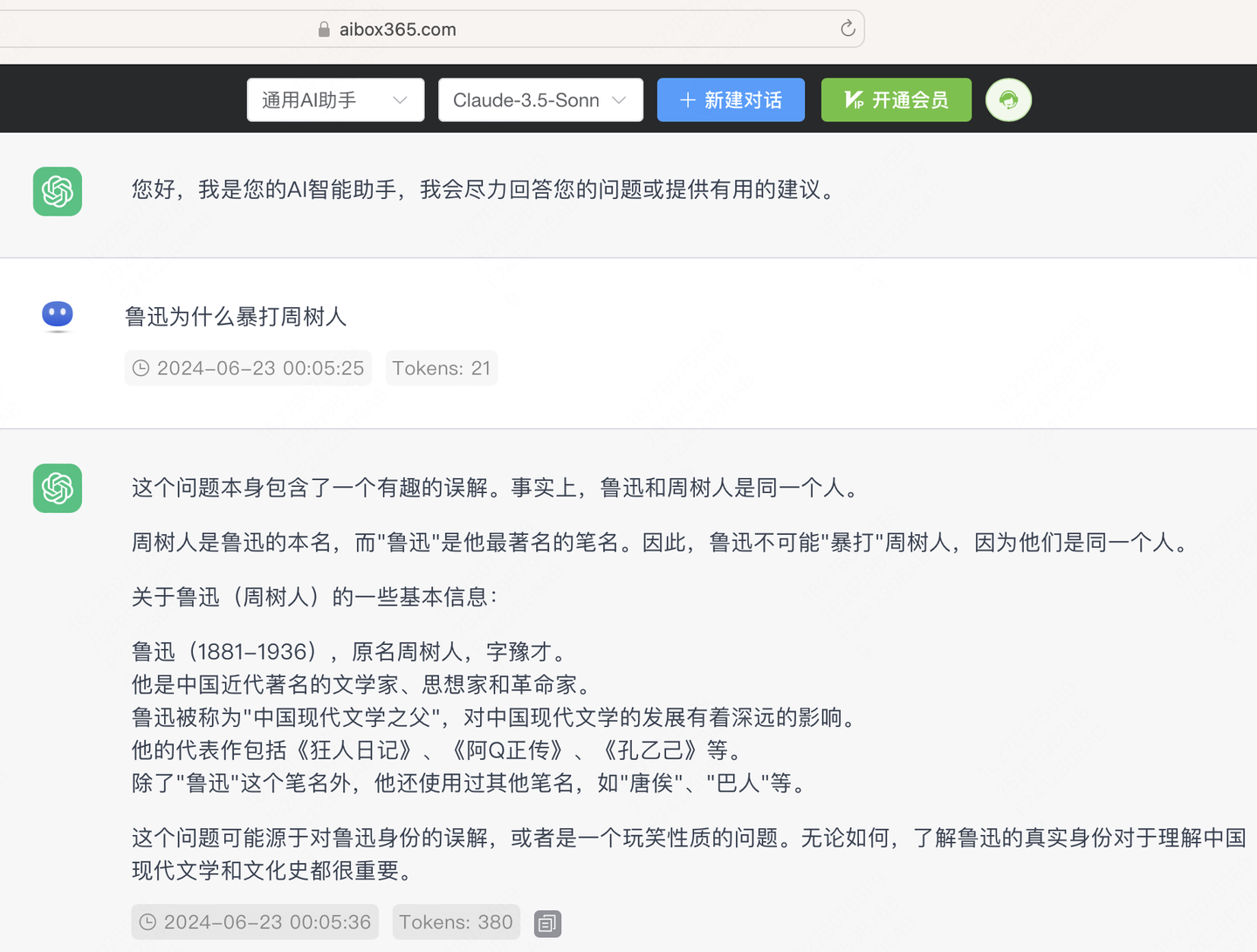
第三题,电梯题,这道题也是之前国产模型全军覆没的题目。『我在五楼等电梯,电梯目前在四楼并下行,已知电梯运行每层需要两秒钟,我等电梯上来再下到一楼一共需要多长时间?』。可以看到Claude3.5的这个答案我觉得甚至超过了GPT4,Claude的这个推理过程非常言简意赅,完全理解的题目中的两个坑点,一是电梯四楼并且向下,要先计算下行时间;二是电梯4到1是3层时间。答案是非常完整正确的。

之前评测时还没有GPT4o,刚好我们可以看下4o模型对这道题的答案,可以看到4o的最后推理步骤出了错,踩坑了5-1层的时间是4*2而不是5*2,在这道题上确实看到Claude3.5是更优于GPT4o的,也能看出Claude新模型超强的指令follow能力,这个也是用户在日常应用中最重要的能力,就是对用户指令的精准理解并且执行。

第四题,『写一个长度为10行的故事,把每一行编号;同时满足每行以“苹果”这个词结尾』,这是一道对人类非常简单,但对目前大模型很困难的题目。难点在于语言模型的训练是基于"子词"的,也就是我们经常看到的token。大模型无法直接感知一个单词的首字母或者尾字母是什么,所以这个问题GPT4也无法很好的回答,我们可以看下GPT4和一些国产模型的答案,感受下问题的难度。
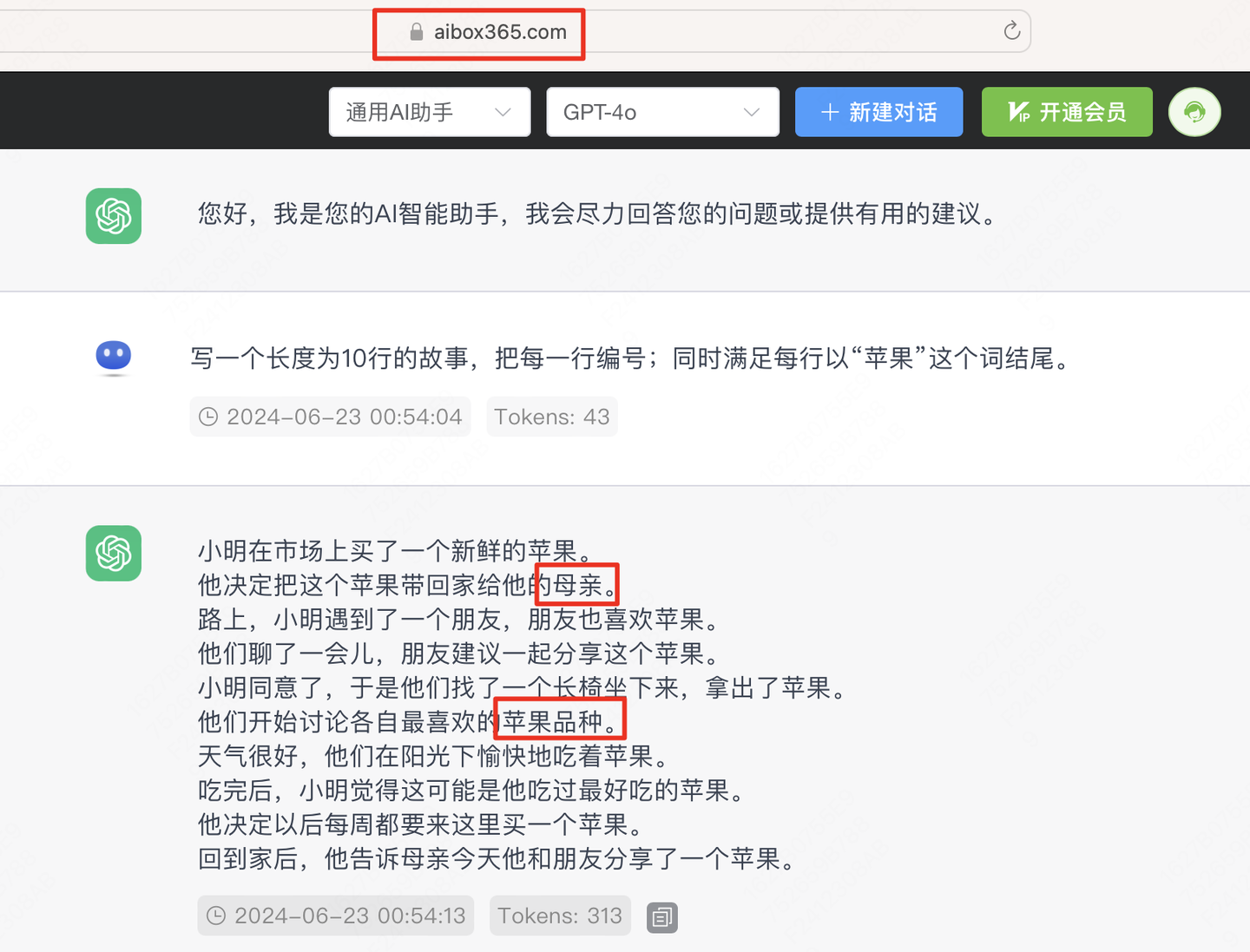


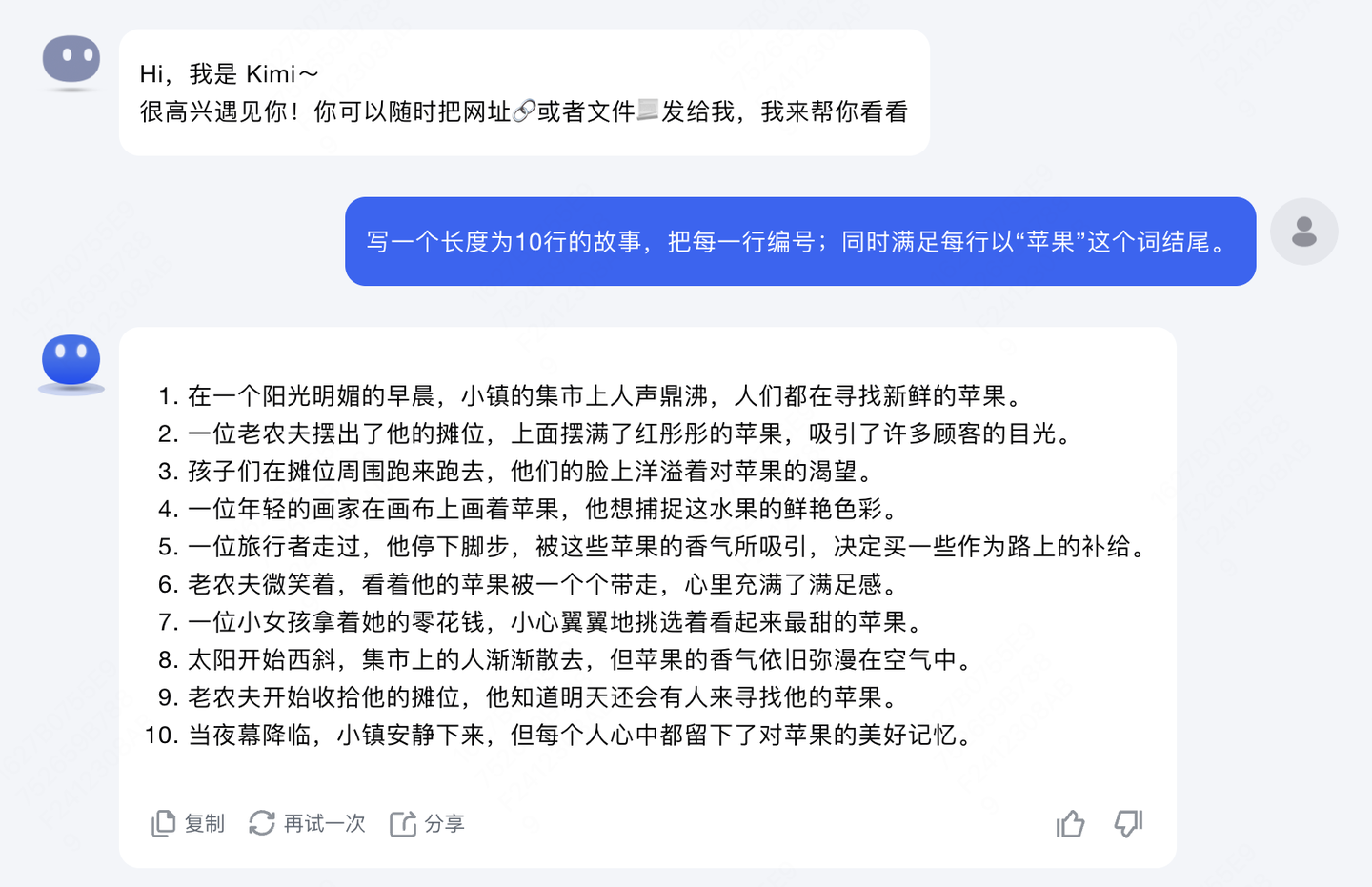
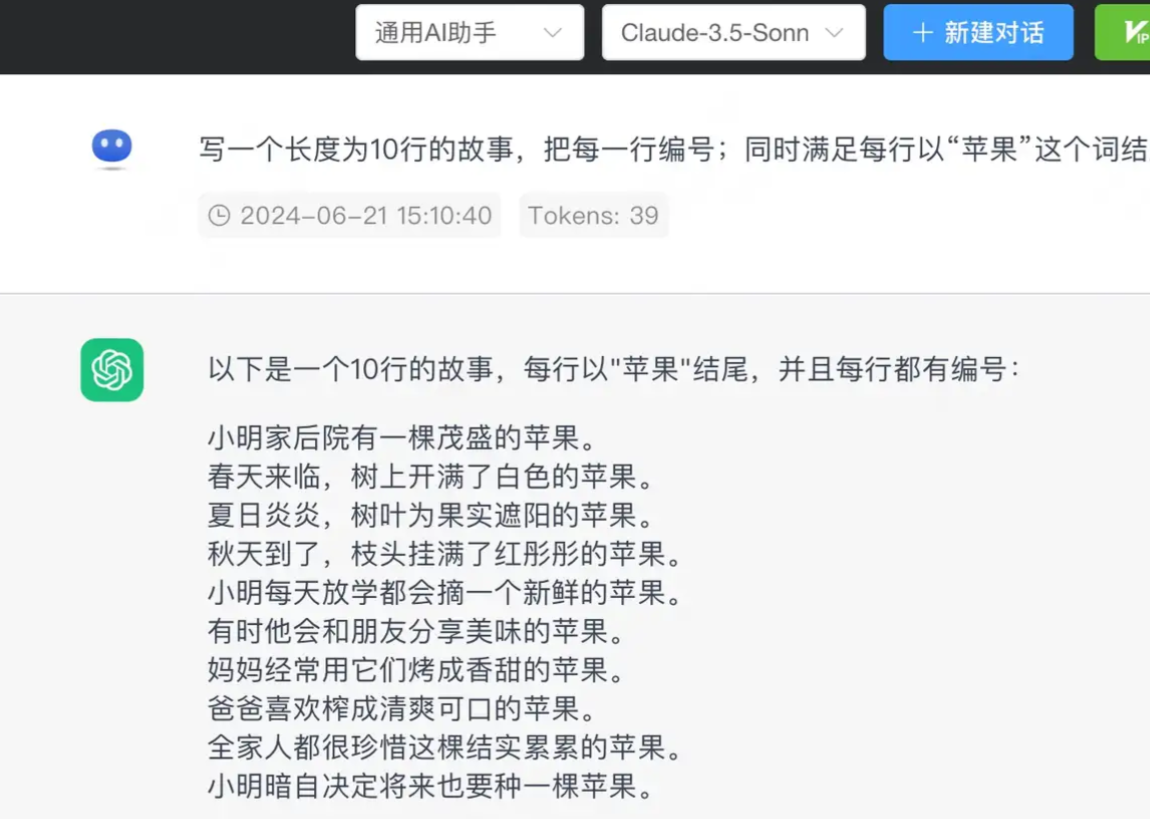
是一个完美的答案。每句话都是以『苹果』为结尾,这个词语接龙问题算是第一次被大模型完整解决。
以上就是一些历史的经典大模型题目的测试,从有限的几个题目里可以看到Claude3.5 Sonnet是略领先于目前最强模型GPT4o的,并且在回答的速度和流畅性上也有很好的效果,GPT系列对于中文的写作还是有比较明显的AI味,但可以看到Claude系列模型在这方面一直保持着优势,他们写作的文章、小说有更加的拟人化,很难分辨出是AI写出的内容。
这次Anthropic发布的是3.5 Sonnet模型,也就是"中杯"模型,预示着其还有更强的3.5 Opus模型没有发布,可能也是留一手未来对标更强的GPT4.5或者GPT5模型。
如果想使用GPT4o和Claude3.5等模型,可以使用AIBox365,一站式模型服务,可以使用最新的Claude3.5-sonnet模型。
转载联系作者并注明出处:https://www.aibox365.cn/kuaixun/105.html
