在社交媒体上预热了数月,并以“草莓计划”代号隐秘操作后,OpenAI终于发布了备受期待的新语言模型——它被命名为“o1”。
有趣的是,他们并未选择GPT-5或GPT-4.1这样的命名。那么,为什么是o1呢?
OpenAI解释道,这些新模型的进展非常显著,以至于他们决定将版本号重置为1:
“But for complex reasoning tasks this is a significant advancement and represents a new level of AI capability. Given this, we are resetting the counter back to 1 and naming this series OpenAI o1.”
这些模型的主要特点是能够进行复杂任务的思考和推理,解决更具挑战性的问题。因此,虽然它的反应速度可能不会特别快,但能够提供比之前模型更加优质和合乎逻辑的答案。
o1系列模型包含两种版本:o1-mini和o1-preview。
- o1-preview:这是即将发布的顶级o1模型的预览版本。在AI推理领域,o1-preview有了明显的进展。
- o1-mini:这是一个更高速且经济实惠的模型,尤其在编程任务上表现优异。作为较小的版本,o1-mini相比o1-preview节省了80%的成本,同时保持了强大的推理能力。
OpenAI强调,这些新模型通过强化学习进行了训练,能够执行复杂的推理任务。但在大语言模型的背景下,推理能力具体意味着什么呢?
推理是如何运作的?
就像人类在回答棘手问题时会深思熟虑一样,o1在尝试解决问题时会运用思维链。
它学会了识别并纠正自己的错误,将复杂的步骤分解成更简单的部分,当当前方法不奏效时,它会尝试不同的策略。
关键在于,推理允许模型在生成最终回答前考虑多种方法。
这个过程包括以下步骤:
- 生成推理标记
- 产生可见的完成标记作为答案
- 从上下文中移除推理标记
移除推理标记能让上下文保持聚焦于核心信息。
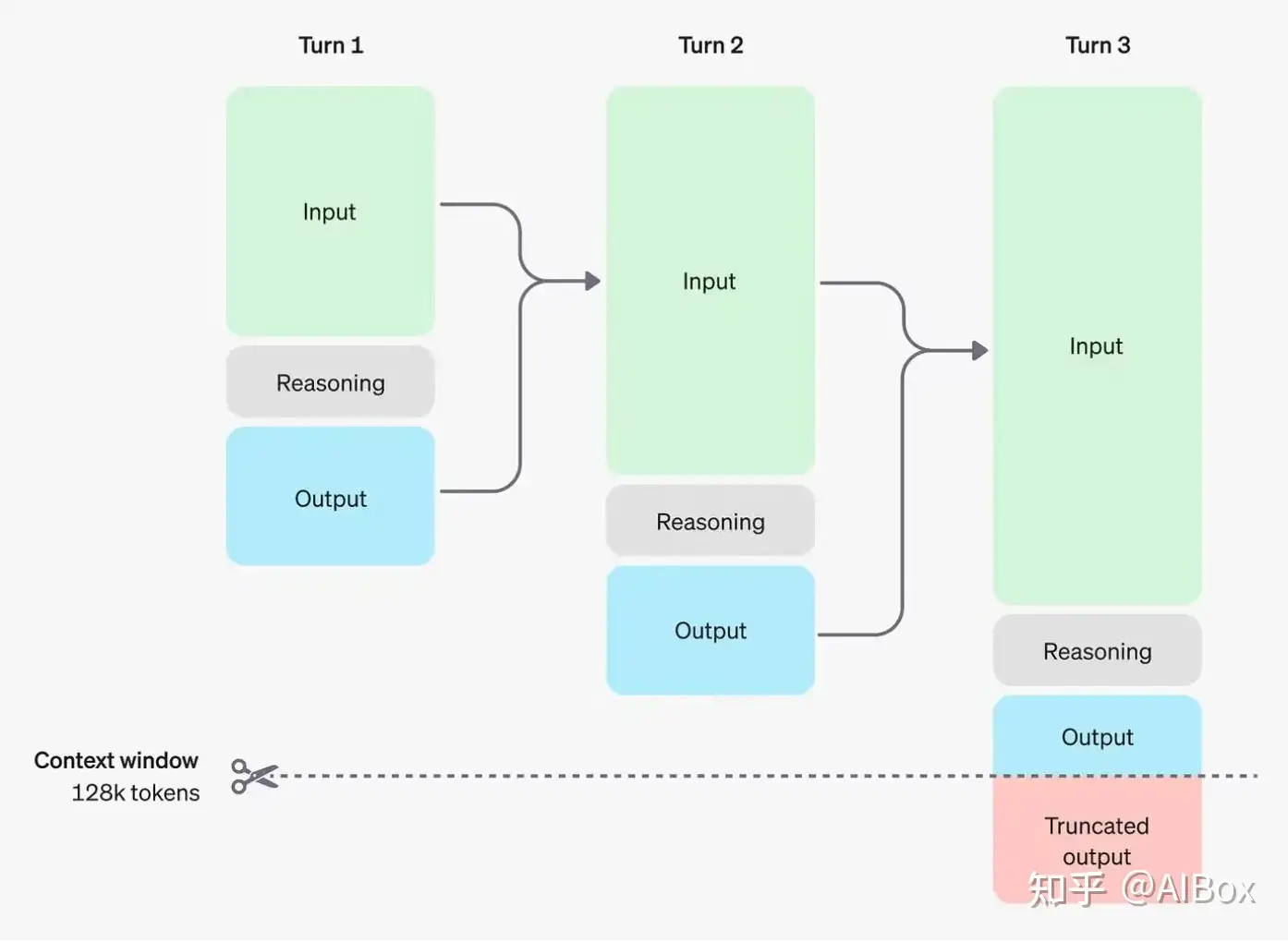
注意:虽然推理标记在API中不可见,但它们仍然占用模型上下文窗口中的空间,并计入输出标记的费用。
NVIDIA高级研究员Jim Fan指出,尽管这种方法可能速度较慢,但我们终于看到了推理时间扩展范式在生产环境中得到普及和应用。
Jim提出了几个精辟的观点:
- 智能推理不一定需要超大模型。目前很多大模型的参数主要用来存储事实知识,以便在回答常规问题时表现出色。但其实我们可以把推理能力和知识分开。想象一个小巧的”推理核心”,它懂得如何使用各种工具(比如网络搜索或代码检查工具)来获取需要的信息。这样做可能会大大减少训练AI所需的计算资源。
- 新模型把大部分计算工作从训练阶段转移到了实际使用阶段。你可以把大语言模型想象成一个基于文字的”模拟世界”。当模型解决问题时,它会在这个”模拟世界”里尝试各种可能的方法和情况。通过不断尝试,模型最终能找到最好的解决方案。这个过程有点像下棋软件(比如AlphaGo)在脑中模拟多种走法来选择最佳着棋。
o1与GPT-4o相比如何?
为了评估o1模型相对于GPT-4o的表现,OpenAI进行了一系列多样化的人类考试和机器学习基准测试。
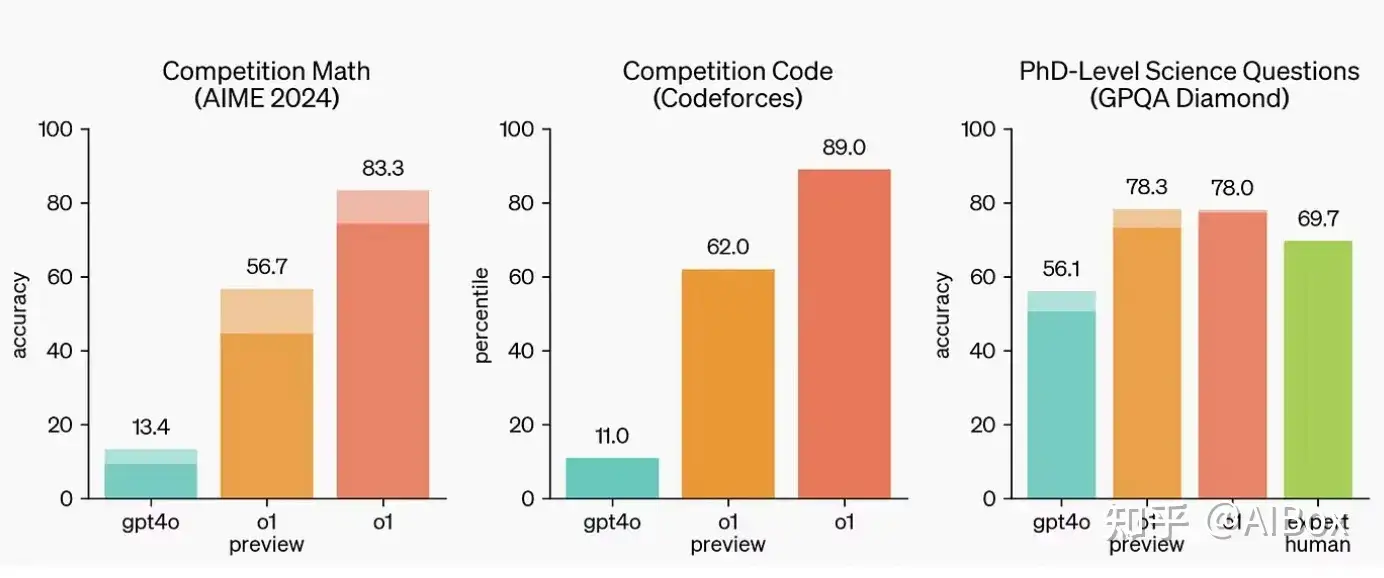
上图清楚地展示了o1在涉及数学、编程和科学问题的复杂推理基准测试中,大幅超越了GPT-4o。
在评估新发布的o1模型时,OpenAI发现它们在GPQA-diamond基准测试(智力测试,评估化学、物理和生物学领域的专业知识)中表现出色。
为了将模型的表现与人类进行对比,OpenAI邀请了持有博士学位的专家回答相同的GPQA-diamond问题。
令人惊叹的是,o1超越了这些人类专家,成为首个在此基准测试中做到这一点的模型。虽然这并不意味着o1在所有方面都优于博士,但它确实表明,该模型在解决某些预期博士能够处理的问题上更加熟练。
你可以在[这里]阅读更多关于o1模型的技术报告。
现在,让我们通过一个经典问题来比较o1和之前的GPT-4o模型的表现:计算”strawberry”这个词中”r”的数量。
Prompt: How many ‘r’ letter are in the word strawberry?
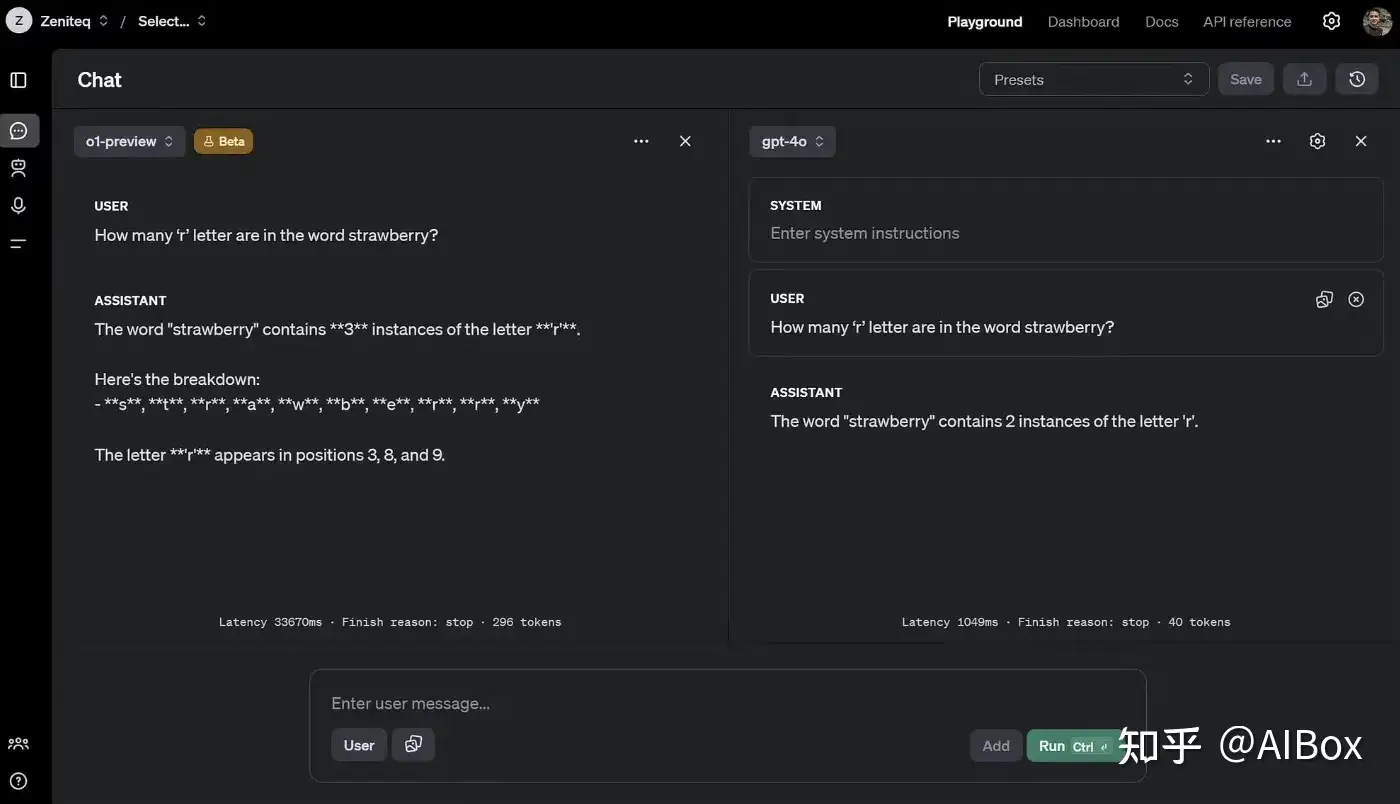
- o1用了33秒和296个标记来解决这个问题,给出了正确答案。
- GPT-4o用时不到一秒,消耗了39个标记,但未能通过测试。
让我们再试一个。这次,我们要求两个模型列出名称中第三个位置是字母’A’的国家。
Prompt: Give me 5 countries with letter A in the third position in the name

再次,o1给出了正确答案,尽管比GPT-4o花费了更长时间来”思考”。
o1并非完美无缺
即便是Sam Altman也承认o1仍有缺陷和局限性。它在首次使用时可能给人留下深刻印象,但随着使用时间的增加,你可能会发现它并非完美。
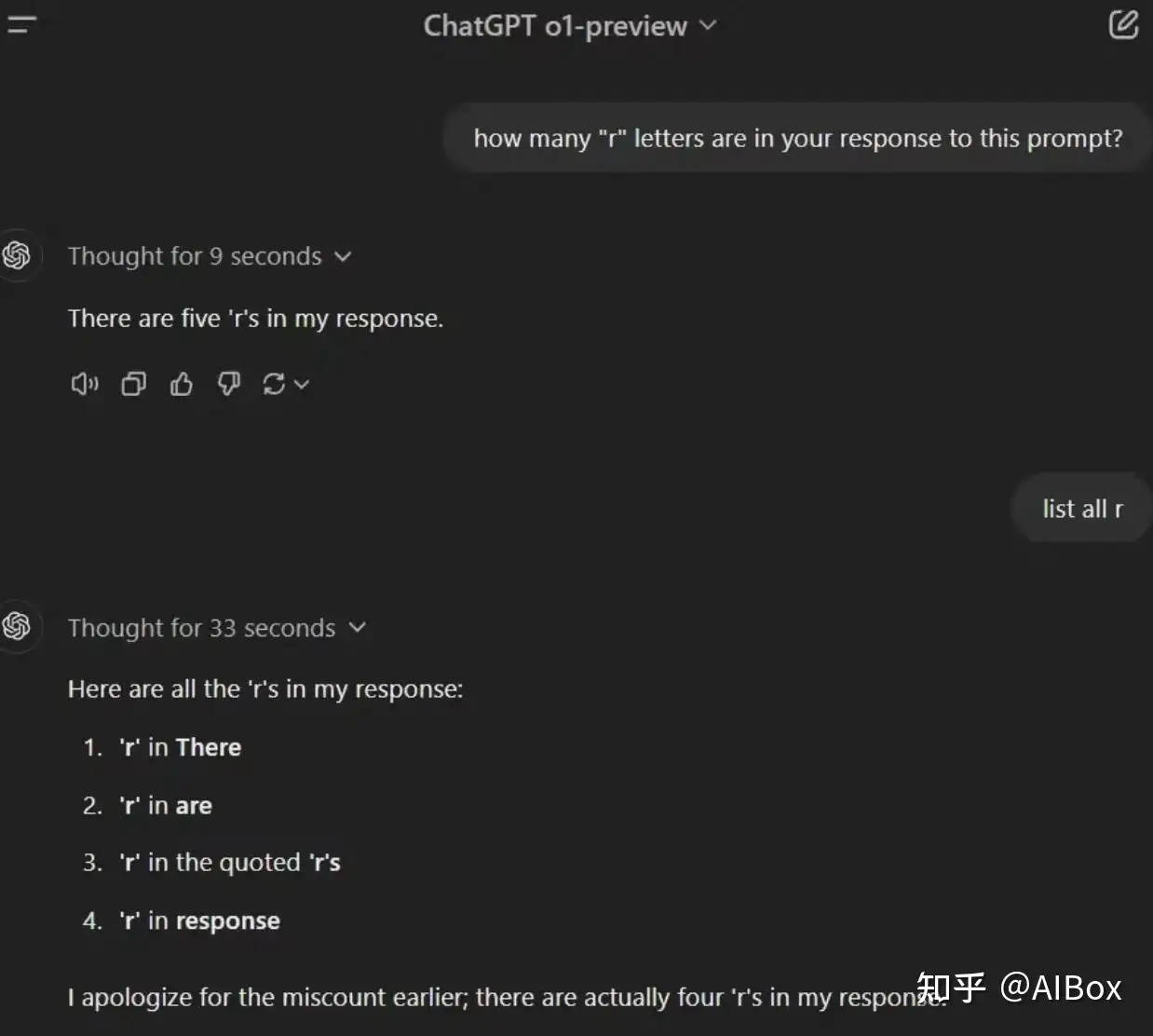
有时,它仍然会犯错 — — 即使面对像询问其回答中有多少个’r’这样简单的问题。
另一点需要注意的是,虽然o1模型在推理能力上有重大突破,但并不意味着它能在所有场景下取代GPT-4o。
对于需要图像输入、函数调用或持续快速响应时间的应用,GPT-4o和GPT-4o mini模型仍然是更合适的选择。
对于开发者来说,o1的一些API参数目前还不可用:
- Modalities:仅支持文本,不支持图像。
- Message types:仅支持用户和助手消息,不支持系统消息。
- Streaming:不支持。
- Tools:不支持工具、函数调用和响应格式参数。
- Logprobs:不支持。
- Other:temperature、top_p和n固定为1,presence_penalty和frequency_penalty固定为0。
- Assistants and Batch:这些模型在Assistants API或Batch API中不受支持。
如何获取o1模型的访问权限?
o1今天在ChatGPT上向所有Plus和Team用户开放,同时在API中向5级开发者开放。
如果你是免费版ChatGPT用户,OpenAI表示他们计划为所有免费用户提供o1-mini的访问权限,但具体时间表尚未公布。
对于国内用户可以使用AIBox大模型平台,无需模仿,国内直达。除o1外,平台同时支持GPT4、Claude3.5、Gemini1.5模型,可以针对不同场景灵活选用。
AIBox365 - ChatGPT中文版,一站式AI创作平台aibox365.como1模型的提示技巧
如果你习惯了像Claude 3.5 Sonnet、Gemini Pro或GPT-4o这样的模型的常规提示方式,那么提示o1模型需要采取不同的策略。
o1模型在直接明了的提示下表现最佳。一些常见的提示工程技巧,如少样本提示或指示模型”逐步思考”,可能不会提高性能,有时甚至会产生负面影响。
以下是一些最佳实践:
- 保持提示简洁直接:这些模型擅长理解和回应简短、清晰的指令,无需冗长的引导。
- 避免思维链提示:由于这些模型内部已经执行推理,提示它们”逐步思考”或”解释你的推理过程”是多余的。
- 使用分隔符提高清晰度:使用三重引号、XML标签或章节标题等分隔符清楚地标示输入的不同部分,帮助模型正确解释各个部分。
- 在检索增强生成(RAG)中限制额外上下文:在提供额外上下文或文档时,只包括最相关的信息,以防止模型过度复杂化其响应。
结语
不得不说,o1在基于对话的问题解决和内容生成方面表现令人印象深刻。但你知道最让我兴奋的是什么吗?它与像Cursor AI这样的编码助手的集成潜力。
我已经看到有人将他们的API密钥插入Cursor并使用o1为他们编写代码。虽然我还没有亲自尝试,但我非常期待能够体验一下。
从我的初步测试来看,o1的思考、规划和执行能力确实出类拔萃。我们基本上正在见证 agentic coding 系统的ChatGPT时刻。它的新能力带来的影响是深远的。
我真诚地相信,用这个工具构建的全新产品浪潮将与我们之前见过的任何东西都不同。软件开发领域的新可能性令人振奋,我迫不及待地想看看o1在未来几周内将如何彻底改变我们编码和构建应用程序的方式。
转载联系作者并注明出处:https://www.aibox365.cn/kuaixun/126.html
